L3Fnet
"Harnessing Multi-View Perspective of Light Fields for Low-Light Imaging", IEEE TIP 2021
Harnessing Multi-View Perspective of Light Fields for Low-Light Imaging
The project is the official implementation of our IEEE TIP Journal, “Harnessing Multi-View Perspective of Light Fields for Low-Light Imaging”
— Mohit Lamba, Kranthi Kumar Rachavarapu, Kaushik Mitra
A single PDF of the paper and the supplementary is available at arXiv.org.
Light Field (LF) offers unique advantages such as post-capture refocusing and depth estimation, but low-light conditions, especially during night, severely limit these capabilities. We, therefore, propose a deep neural network architecture for Low-Light Light Field (L3F) restoration, which we call L3Fnet. The proposed L3Fnet not only performs the necessary visual enhancement of each LF view but also preserves the epipolar geometry across views. To facilitate learning-based solution for low-light LF imaging, we also collected a comprehensive LF dataset called L3F-dataset. Our code and the L3F dataset are now publicly available for download.

Click to read full Abstract !
Light Field (LF) offers unique advantages such as post-capture refocusing and depth estimation, but low-light conditions severely limit these capabilities.
To restore low-light LFs we should harness the geometric cues present in different LF views, which is not possible using single-frame low-light enhancement techniques. We, therefore, propose a deep neural network architecture for Low-Light Light Field (L3F) restoration, which we refer to as L3Fnet. The proposed L3Fnet not only performs the necessary visual enhancement of each LF view but also preserves the epipolar geometry across views. We achieve this by adopting a two-stage architecture for L3Fnet. Stage-I looks at all the LF views to encode the LF geometry. This encoded information is then used in Stage-II to reconstruct each LF view.
To facilitate learning-based techniques for low-light LF imaging, we collected a comprehensive LF dataset of various scenes. For each scene, we captured four LFs, one with near-optimal exposure and ISO settings and the others at different levels of low-light conditions varying from low to extreme low-light settings. The effectiveness of the proposed L3Fnet is supported by both visual and numerical comparisons on this dataset. To further analyze the performance of low-light reconstruction methods, we also propose an L3F-wild dataset that contains LF captured late at night with almost zero lux values. No ground truth is available in this dataset. To perform well on the L3F-wild dataset, any method must adapt to the light level of the captured scene. To do this we use a pre-processing block that makes L3Fnet robust to various degrees of low-light conditions. Lastly, we show that L3Fnet can also be used for low-light enhancement of single-frame images, despite it being engineered for LF data. We do so by converting the single-frame DSLR image into a form suitable to L3Fnet, which we call as pseudo-LF.
Sample Output
Low-light conditions are a big challenge to Light Field applications. For example, the depth estimate of LF captured in low light is very poor. Our proposed method not only visually restores each of the LF views but also preserves the LF geometry for faithful depth estimation, as shown below (Click to see full resolution image).

Click to see more Results !
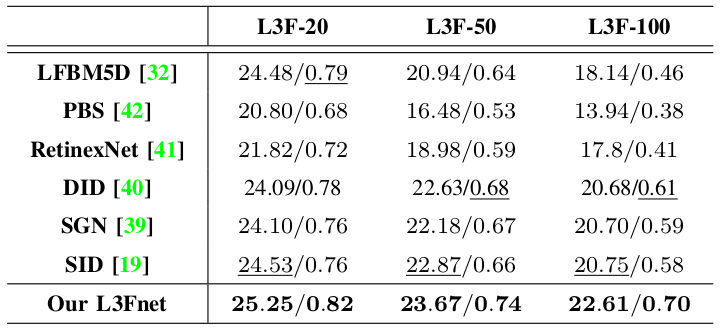
The proposed L3Fnet harnesses information form all the views to produce sharper and less noisy restorations. Compared to our restoration, the existing state-of-the-art methods exhibit considerable amount of noise and blurriness in their restorations. This is substantiated by both qualitative and PSNR/SSIM quantitative evaluations.


The L3F Dataset

Unlike most previous works on low-light enhancement we do not simulate low-light images using Gamma correction or modifying images in Adobe Photoshop. Rather we physically capture Light Field images when the light falling on camera lens is in between 0-20 lux.
L3F-20, L3-50 and L3F-100 dataset
The L3F-dataset used for training and testing comprises of 27 scenes. For each scene we capture one LF with large exposure which then serves as the well-lit GT image. We then capture 3 more LFs captured at 20th, 50th and 100th fraction of the exposure used for the GT image. A detailed descrition of the collected dataset can be found in Section III of the main paper.
The RAW format used by Lytro Illum is very large (400 - 500 MB) and requires several post-processing such as hexagonal to rectilinear transformation before it can be used by L3Fnet. We thus used JPEG compressed images for training and testing. Even after compression each LF is abour 50 MB is size; much larger than even raw DSLR image. Although we do not use raw LF images in this work, we also make the raw LF images public.
Click here to see the central SAIs of all the 27 scenes !
The following scenes are used for TRAINING.


L3F-wild Dataset
The Light Fields captured in this dataset were captured late in the night in almost 0 lux conditions. These scenes were captured with normal ISO and exposure settings as if being captured in bright sunlight in the day. The scenes in the L3F-wild dataset are so dark that no GT was possible. Thus they cannot be used for quantitative evaluation but serves as a real-life qualitative check for methods which claim low-light enhancement.
Click here to see the SAIs restored by our L3Fnet !

How to use the Code ?
The L3F code and dataset is arranged as below,
./L3F
├── L3F-dataset
│ ├── jpeg
│ │ ├── test
│ │ │ ├── 1
│ │ │ ├── 1_100
│ │ │ ├── 1_20
│ │ │ └── 1_50
│ │ └── train
│ │ ├── 1
│ │ ├── 1_100
│ │ ├── 1_20
│ │ └── 1_50
│ └── raw
│ ├── test
│ │ ├── 1
│ │ ├── 1_100
│ │ ├── 1_20
│ │ └── 1_50
│ └── train
│ ├── 1
│ ├── 1_100
│ ├── 1_20
│ └── 1_50
├── L3Fnet
│ ├── expected_output_images
│ ├── demo_cum_test.py
│ ├── train.ipynb
│ └── weights
└── L3F-wild
├── jpeg
└── raw
The jpeg directory contains the decoded LF in .jpeg format and were used in this work. The well-illuminated GT images are present in the directory called 1 and the other folders, namely 1_20, 1_50 and 1_100 contain the low-light LF images with reduced exposure. The original undecoded raw files captured by Lytro Illum can be found in the raw directory. The corresponding raw and .jpeg files have the same file names.
To find the well-lit and low-light image pairs, alphabetically sort the directories by file name. The images are then matched by the same serial number. An example for the L3F-100 datset is shown below,
import os
from PIL import Image
GT_files = sorted(os.walk('L3F/L3F-dataset/jpeg/test/1'))
LowLight_files = sorted(os.walk('L3F/L3F-dataset/jpeg/test/1_100'))
GT_image = Image.open(GT_files[idx]).convert('RGB')
LowLight_image = Image.open(LowLight_files[idx]).convert('RGB')
The code for L3F-net can be found in L3F-net directory. Execute demo_cum_test.py file for a quick demo. This file restores the dark images present in the L3F-100 dataset. The expected output images after excuting this file are given in expected_output_images directory. To successfully execute this file you need to set the following variables.
LowLight_dir:path/to/L3F-100/jpeg/folderGT_dir:path/to/L3F-1/jpeg/folderGPU:Make this flagfalseto execute the file on CPU.
L3F-net can selectively restore SAIs. As restoring all 64 SAIs takes a lot of computation and so in this file we restore only two SAIs to save computation. If you wish to restore more number of SAIs, simply include the desired SAIs index in the choice variable present towards the end of the data loader.
The code for L3Fnet was written using PyTorch 1.3.1 and Python 3.7 running on Ubuntu 16.04 LTS.
Cite us
@ARTICLE{l3fnet,
author={M. {Lamba} and K. K. {Rachavarapu} and K. {Mitra}},
journal={IEEE Transactions on Image Processing},
title={Harnessing Multi-View Perspective of Light Fields for Low-Light Imaging},
year={2021},
volume={30},
pages={1501-1513},
doi={10.1109/TIP.2020.3045617}}